Random Forest

Learning by teaching
Problem with Decision Tree
Decision Trees are highly sensitive to training dataset. A small change in the training dataset might completely change the decision tree. So, a decision tree will work extremely well on training dataset but perform poorly on new samples. The model might fail to generalize and lead to problems of high variance and overfitting.
Random Forest Algorithm
Random Forest is a collection of multiple Decision Trees. It is much less sensitive to the training dataset. The steps of the algorithm are as follows -
Bootstrapping
Bootstrapping is the process of creating new dataset from the original dataset with same number of rows but arranged randomly. Some of the rows may appear more than once and others may not even appear in the bootstrapped dataset. Hence it is called random sampling with replacement. The selection of rows is performed randomly and a row can be selected more than once. The algorithm builds nearly 100 such bootstrapped dataset.
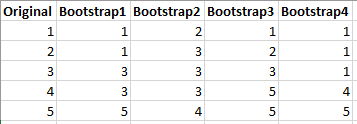
Only row ids are shown in the example.
Further, we will build a decision tree for each bootstrapped dataset. While building a decision tree, we only consider few of the features. These features are also selected randomly for each bootstrapped dataset. The best practice is to select number of subset features close to the square root of total features.
Aggregation
To make a prediction, the sample is passed through all the decision trees. At the end, the result from all the decision trees is combined. In the classification problem, the majority class is taken as the predicted value and in the regression problem, the average value of the results is taken. This process of combining results from multiple models is called aggregation. In the random forest we perform Bootstrapping + Aggregation. Hence it is called bagging technique.
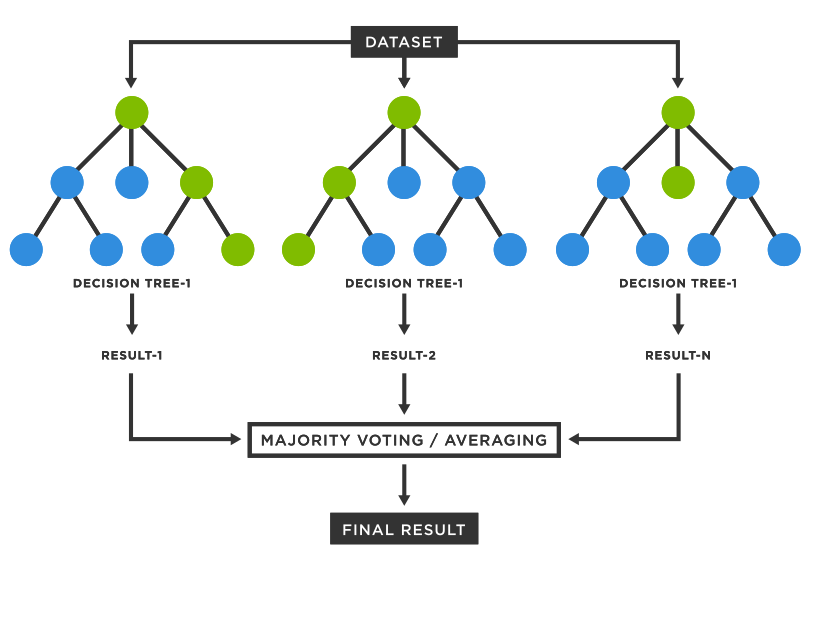
So, it is called random forest because we perform random selection of data as well as feature and we use multiple decision trees as our base model. Bootstrapping ensures that we are not using the same data for every tree and random selection of feature helps to reduce the creation of same or similar trees with the same decision nodes. So, our model will be less sensitive to the training dataset and also solves the issue of high variance.
While creating a new bootstrapped dataset, there could be some of the entries which didn't get selected. These entries are called out-of-bag dataset. These out-of-bag samples are then used to measure the accuracy of the random forest.



