Decision Tree

Learning by teaching
Introduction
Decision Tree is a binary tree like data structure which recursively splits the dataset until we are left with pure leaf nodes. The internal nodes represent the conditions and the leaf nodes represent the decision based on the conditions. Decision Tree is used for both classification and regression problems. Decision Tree is a supervised learning algorithm.
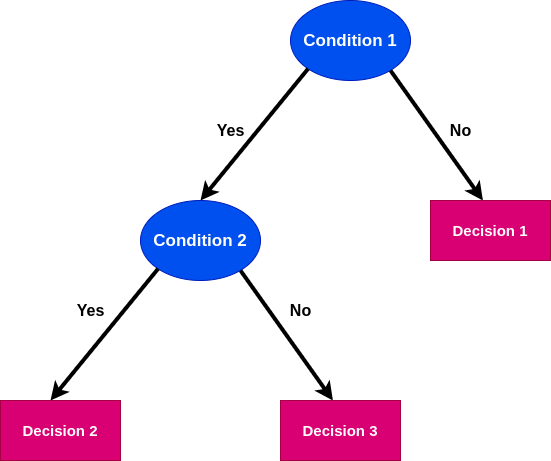
A decision tree might look like a bunch of nested if-else statements. Technically, its true that a decision tree is just a bunch of if-else statements but we need to find the correct conditions. For a dataset, there could be a lot of possible splitting conditions. Our model needs to learn which features to take and the corresponding correct threshold values to optimally split the data. This is where machine learning comes into the play.
Classification Algorithm
The model will find the most optimal split that maximizes information gain. To find information gain, we need to understand the information contained in a state. The model uses Entropy or Gini Index to measure the information contained in a state.
Entropy
Entropy gives the measure of randomness or impurity in the information being processed. Higher the entropy, more is the randomness which leads in harder to draw any conclusion from that information.
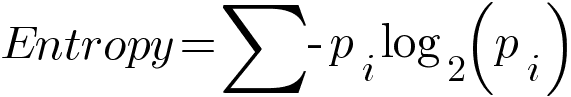
pi is the probability of class i
We calculate the entropy of nodes and find the information gain corresponding to each split using the formula -
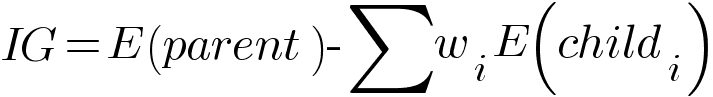
Where E(parent) is the entropy of parent node and E(childi) is the entropy of child nodes. wi is the relative size of child node with respect to parent node. The model compares every possible split and finds the best split which gives the highest information gain. So the model traverses every possible feature and feature value to search for the best feature and corresponding threshold.
Gini Index
In place of Entropy, we can use Gini Index to measure the information. Gini saves computation time because entropy uses logarithm.
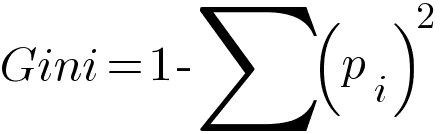
Then to calculate information gain, we use Gini Index instead of Entropy.
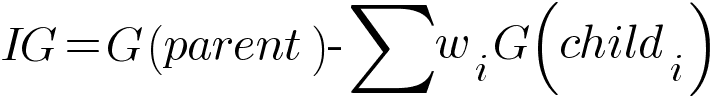
For more complex data, in our decision tree we might not have leaf nodes which gives only one type of class. In such cases, the model performs majority voting and assign the majority class to the test point.
Regression Algorithm
The difference between the two algorithms lies in the measure of information and the way final prediction is made.
The best split is measured by Variance Reduction. Variance is used as the measure of impurity in regression problems instead of entropy/gini in classification problems.
The formula for variance is -
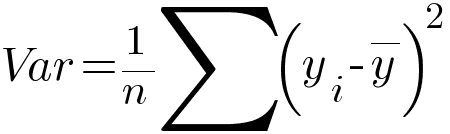
Higher the variance, more is the impurity present. The formula for variance reduction is similar to the formula of information gain seen in the classification algorithm.
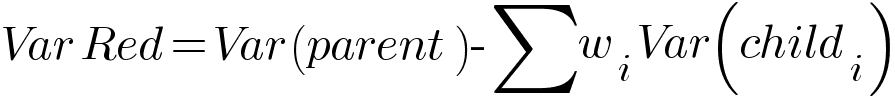
The model chooses the split which has the highest variance reduction. The model evaluates the variance of every possible split and selects the best one. This process happens recursively. To predict the new data point, the model calculates the average of all y values present in the leaf node.
Important Note
It is important to note that Decision Tree is a Greedy Algorithm. It selects the current best split that maximizes the information gain. It does not backtrack and change a previous split. So, all the following splits will depend on the current one which does not guarantee that we will get the most optimal tree. But greedy search makes our computation lot faster and it works really good.



